Pipelining is a technique used in computer architecture to make CPUs work faster and more efficiently. But how does a pipeline work in computer architecture? It is simple, pipelining divides a task into smaller steps and completes them in stages.
Like an assembly line in a factory, pipelines allow multiple instructions to be processed simultaneously, saving time and improving performance.
What is Pipelining?
Pipelining in computer architecture means splitting a process into smaller parts and handling each separately. Each part, called a “stage,” works on a small piece of the task. For example, while one part fetches instructions, another decodes them, and a third executes them.
Pipelining aims to increase the number of instructions the CPU handles in a given time. It helps make the computer faster and more efficient.
Basics of Computer Architecture
To understand pipelining, we first need to know the basics of computer architecture. A CPU performs tasks by following instructions. These instructions go through a cycle of three main steps:
- Fetch: The CPU gets the instruction from memory.
- Decode: It reads and understands the instructions.
- Execute: The CPU performs tasks like adding numbers or moving data.
Without pipelining, the CPU finishes one instruction before starting the next. This wastes time.
Stages in the Pipeline Process
Pipelining splits the instruction cycle into separate stages. These stages work together like parts of an assembly line:
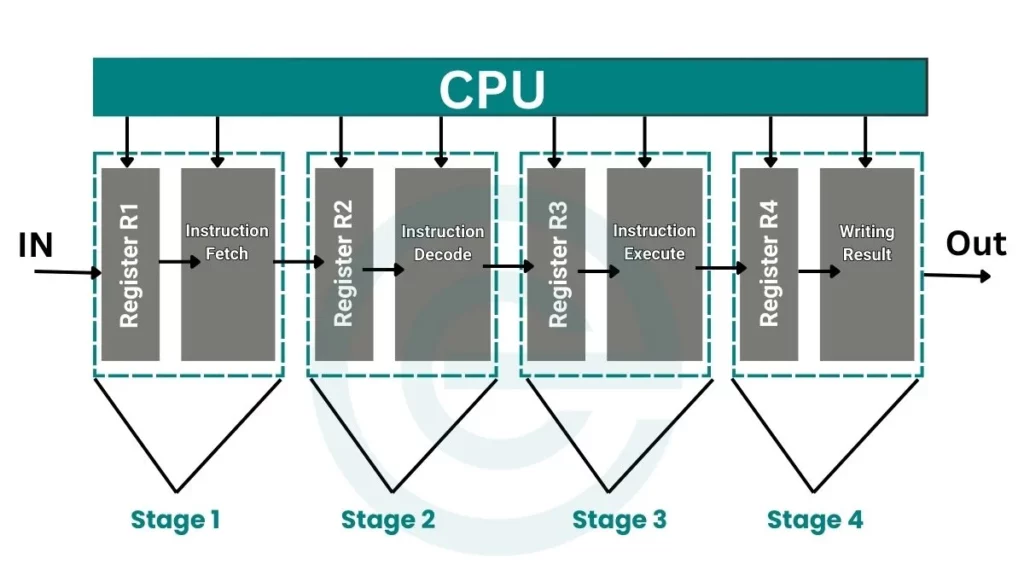
1. Instruction Fetch
The first step is fetching an instruction from memory. The CPU retrieves the instruction it needs to process. This step is like gathering ingredients before cooking.
2. Instruction Decode
In this step, the instruction is analyzed. The CPU figures out what action needs to be taken. For example, it might need to add numbers, move data, or perform a logical operation.
3. Execute
The execute stage is where the instruction is carried out. If it’s a calculation, the CPU performs the math here. This is like cooking the ingredients.
4. Memory Access
If the instruction needs data stored in memory, it is retrieved in this step. For example, if a program requires numbers from memory, the CPU fetches them here.
5. Write Back
Finally, the instruction’s result is saved. It could involve updating a register or writing data back to memory. The task is complete, and the CPU moves on to the next instruction.
A Simple Example of Pipelining
Imagine washing clothes at home:
- Step 1: Put clothes in the washer.
- Step 2: Load the dryer with washed clothes while the washer runs.
- Step 3: While the dryer runs, fold clean clothes.
In this process, tasks overlap. You immediately get all the clothes to dry before folding. Similarly, in pipelining, tasks overlap to save time.
Types of Pipelining
Pipelining is not limited to one type. Different tasks require different pipelining techniques. Here are three common types:
1. Instruction-Level Pipelining: This is the most common type. It breaks down instructions into miniature stages, like fetching, decoding, and executing. Each stage runs in a separate pipeline.
2. Arithmetic Pipelining: Used for mathematical operations. For example, an enormous multiplication task can be split into smaller steps, processed faster, and completed efficiently.
3. Data pipelines: It focuses on smooth data transfer between the CPU and memory. They ensure that data is ready when needed, avoiding delays.
Advantages of Pipelining
Pipelining offers several benefits that make it a crucial feature in modern processors:
- Faster Processing: Multiple instructions are handled simultaneously, increasing the execution speed.
- Better Resource Utilization: All CPU parts are active and working, reducing idle time.
- Increased Throughput: More instructions are completed quickly, improving overall performance.
- Scalability: Pipelining can be applied to different processors and workloads, making it versatile.
Challenges in Pipelining
While pipelining improves efficiency, it also introduces certain challenges called hazards. These challenges can disrupt the smooth flow of instructions in the pipeline.
1. Data Hazards: These occur when instructions depend on the results of previous instructions. For example, if one instruction needs the output of another, the pipeline might need to pause.
2. Control Hazards: Branching instructions, like “if” conditions, can disrupt the pipeline’s flow. The CPU might need to wait until it knows which path to take.
3. Structural Hazards occur: when two instructions need the same hardware resource, like memory or a register, simultaneously.
FAQs
What is branch prediction in pipelining?
Branch prediction is a technique where the CPU guesses the outcome of a decision or branch. This helps avoid delays in the pipeline. If the guess is wrong, the pipeline adjusts and continues processing.
What are the main stages of a pipeline?
1. Fetch: Retrieving the instruction from memory.
2. Decode: Interpreting the instruction.
3. Execute: Operating.
4. Write Back: Storing the result.
Where is pipelining used in real life?
1. Modern CPUs for faster instruction processing.
2. GPUs for rendering images and videos.
3. Networking devices to process multiple data packets.
4. Data-intensive applications like AI and databases.
